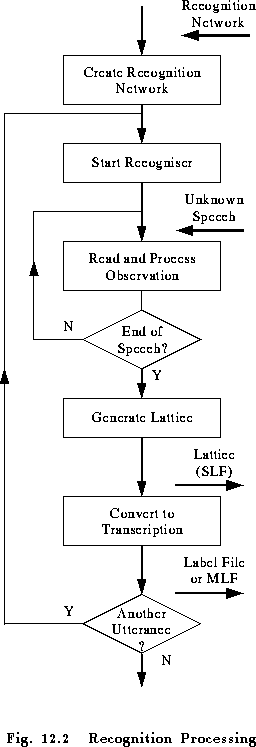
The decoding process itself is performed by a set of core functions provided within the library module HREC . The process of recognising a sequence of utterances is illustrated in Fig. 12.2.
The first stage is to create a recogniser-instance. This is a data structure containing the compiled recognition network and storage for storing tokens. The point of encapsulating all of the information and storage needed for recognition into a single object is that HREC is re-entrant and can support multiple recognisers simultaneously. Thus, although this facility is not utilised in the supplied recogniser HVITE , it does provide applications developers with the capability to have multiple recognisers running with different networks.
Once a recogniser has been created, each unknown input is processed by first executing a start recogniser call, and then processing each observation one-by-one. When all input observations have been processed, recognition is completed by generating a lattice. This can be saved to disk as a standard lattice format (SLF) file or converted to a transcription.
The above decoder organisation is extremely flexible and this is demonstrated by the HTK tool HVITE which is a simple shell program designed to allow HREC to be driven from the command line.
Firstly, input control in the form of a recognition network allows three distinct modes of operation
The second source of flexiblity lies in the provision of multiple tokens and recognition output in the form of a lattice. In addition to providing a mechanism for rescoring, lattice output can be used as a source of multiple hypotheses either for further recognition processing or input to a natural language processor. Where convenient, lattice output can easily be converted into N-best lists.
Finally, since HREC is explicitly driven step-by-step at the observation level, it allows fine control over the recognition process and a variety of traceback and on-the-fly output possibilities.
For application developers, HREC and the HTK library modules on which it depends can be linked directly into applications. It will also be available in the form of an industry standard API. However, as mentioned earlier the HTK toolkit also supplies a tool called HVITE which is a shell program designed to allow HREC to be driven from the command line. The remainder of this chapter will therefore explain the various facilities provided for recognition from the perspective of HVITE.