This section provides a basic introduction to the HTK Standard Lattice Format (SLF). SLF files are used for a variety of functions some of which lie beyond the scope of the standard HTK package. The description here is limited to those features of SLF which are required to describe word networks suitable for input to HNET. The following Chapter describes the further features of SLF used for representing the output of a recogniser. For reference, a full description of SLF is given in Chapter 16.
A word network in SLF consists of a list of nodes and a list of arcs.
The nodes represent words and the arcs represent the transition between
words .
Each node and arc definition is written on a single line and
consists of a number of fields. Each field specification consists of a
``name=value'' pair. Field names can be any length but all commonly used
field names consist of a single letter. By convention, field names
starting with a capital letter are mandatory whereas field names
starting with a lower-case letter are optional. Any line beginning with
a # is a comment and is ignored.
.
Each node and arc definition is written on a single line and
consists of a number of fields. Each field specification consists of a
``name=value'' pair. Field names can be any length but all commonly used
field names consist of a single letter. By convention, field names
starting with a capital letter are mandatory whereas field names
starting with a lower-case letter are optional. Any line beginning with
a # is a comment and is ignored.
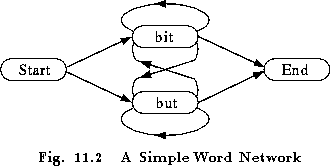
The following example should illustrate the basic format of an SLF word network file. It corresponds to the network illustrated in Fig 11.2 which represents all sequences consisting of the words ``bit'' and ``but'' starting with the word ``start'' and ending with the word ``end''. As will be seen later, the start and end words will be mapped to a silence model so this grammar allows speakers to say ``bit but but bit bit ....etc''.
# Define size of network: N=num nodes and L=num arcs
N=4 L=8
# List nodes: I=node-number, W=word
I=0 W=start
I=1 W=end
I=2 W=bit
I=3 W=but
# List arcs: J=arc-number, S=start-node, E=end-node
J=0 S=0 E=2
J=1 S=0 E=3
J=2 S=3 E=1
J=3 S=2 E=1
J=4 S=2 E=3
J=5 S=3 E=3
J=6 S=3 E=2
J=7 S=2 E=2
Notice that the first line which defines the size of the network must be
given before any node or arc definitions.
A node is a network start node if it has no predecessors,
and a node is network end node if it has no successors.
There must be one and only one network start node and one network
end node.
In the above, node 0 is a network start node and node 1 is a
network end node.
The choice of the names ``start'' and ``end'' for these nodes
has no significance.
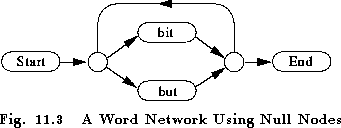
A word network can have null nodes indicated by the special predefined word name !NULL. Null nodes are useful for reducing the number of arcs required. For example, the Bit-But network could be defined as follows
# Network using null nodes
N=6 L=7
I=0 W=start
I=1 W=end
I=2 W=bit
I=3 W=but
I=4 W=!NULL
I=5 W=!NULL
J=0 S=0 E=4
J=1 S=4 E=2
J=2 S=4 E=3
J=3 S=2 E=5
J=4 S=3 E=5
J=5 S=5 E=4
J=6 S=5 E=1
In this case, there is no significant saving, however, if there
were many words in parallel, the total number of arcs would be
much reduced by using null nodes to form common start and end points for
the loop-back connections.
By default, all arcs are equally likely. However, the optional field l=x can be used to attach the log transition probability x to an arc. For example, if the word ``but'' was twice as likely as ``bit'', the arcs numbered 1 and 2 in the last example could be changed to
J=1 S=4 E=2 l=-1.1
J=2 S=4 E=3 l=-0.4
Here the probabilities have been normalised to sum to 1, however,
this is not necessary. The recogniser simply adds the scaled log probability
to the path score and hence it can be regarded as an additive
word transition penalty.