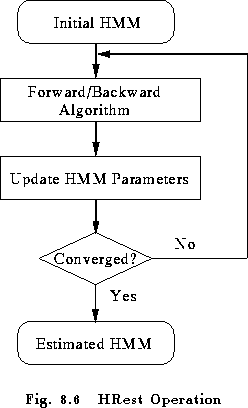
HREST is the final tool in the set designed to manipulate isolated unit HMMs. Its operation is very similar to HINIT except that, as shown in Fig 8.6, it expects the input HMM definition to have been initialised and it uses Baum-Welch re-estimation in place of Viterbi training. This involves finding the probability of being in each state at each time frame using the Forward-Backward algorithm. This probability is then used to form weighted averages for the HMM parameters. Thus, whereas Viterbi training makes a hard decision as to which state each training vector was ``generated'' by, Baum-Welch takes a soft decision. This can be helpful when estimating phone-based HMMs since there are no hard boundaries between phones in real speech and using a soft decision may give better results. The mathematical details of the Baum-Welch re-estimation process are given below in section 8.7.
HREST is usually applied directly to the models generated by HINIT. Hence for example, the generation of a sub-word model for the phone ih begun in section 8.2 would be continued by executing the following command
HRest -S trainlist -H dir1/globals -M dir2 -l ih -L labs dir1/ihThis will load the HMM definition for ih from dir1, re-estimate the parameters using the speech segments labelled with ih and write the new definition to directory dir2.
If HREST is used to build models with a large number of mixture components per state, a strategy must be chosen for dealing with defunct mixture components. These are mixture components which have very little associated training data and as a consequence either the variances or the corresponding mixture weight becomes very small. If either of these events happen, the mixture component is effectively deleted and provided that at least one component in that state is left, a warning is issued. If this behaviour is not desired then the variance can be floored as described previously using the -v option (or a variance floor macro) and/or the mixture weight can be floored using the -w option.
Finally, a problem which can arise when using HREST to initialise sub-word models is that of over-short training segments . By default, HREST ignores all training examples which have fewer frames than the model has emitting states. For example, suppose that a particular phone with 3 emitting states had only a few training examples with more than 2 frames of data. In this case, there would be two solutions. Firstly, the number of emitting states could be reduced. Since HTK does not require all models to have the same number of states, this is perfectly feasible. Alternatively, some skip transitions could be added and the default reject mechanism disabled by setting the -t option. Note here that HINIT has the same reject mechanism and suffers from the same problems. HINIT, however, does not allow the reject mechanism to be suppressed since the uniform segmentation process would otherwise fail.