One limitation of using HINIT for the initialisation of sub-word models is that it requires labelled training data. For cases where this is not readily available, an alternative initialisation strategy is to make all models equal initially and move straight to embedded training using HEREST. The idea behind this so-called flat start training is similar to the uniform segmentation strategy adopted by HINIT since by making all states of all models equal, the first iteration of embedded training will effectively rely on a uniform segmentation of the data.
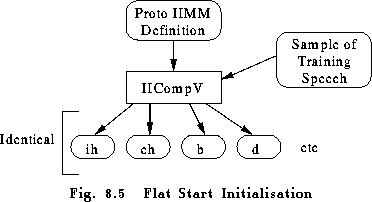
Flat start initialisation is provided by the HTK tool HCOMPV whose operation is illustrated by Fig 8.5. The input/output of HMM definition files and training files in HCOMPV works in exactly the same way as described above for HINIT. It reads in a prototype HMM definition and some training data and outputs a new definition in which every mean and covariance is equal to the global speech mean and covariance. Thus, for example, the following command would read a prototype definition called proto, read in all speech vectors from data1, data2, data3, etc, compute the global mean and covariance and write out a new version of proto in dir1 with this mean and covariance.
HCompV -m -H globals -M dir1 proto data1 data2 data3 ...
The default operation of HCOMPV is only to update the covariances of the HMM and leave the means unchanged. The use of the -m option above causes the means to be updated too. This apparently curious default behaviour arises because HCOMPV is also used to initialise the variances in so-called Fixed-Variance HMMs. These are HMMs initialised in the normal way except that all covariances are set equal to the global speech covariance and never subsequently changed.
Finally, it should be noted that HCOMPV can also be used to generate variance floor macros by using the -f option.