Thesis
I defended my thesis, Characterization of the singing voice from polyphonic recordings, on January 10, 2011.
- abstract
- audio demo (less than a minute!)
Abstract
In order to study the singing voice, researchers have traditionally relied upon lab-based experiments and/or simplified models. Neither of these methods can reasonably be expected to always capture the essence of true performances in environmentally valid settings. Unfortunately, true performances are generally much more difficult to work with because they lack precisely the controls that lab setups and artificial models afford. In particular, true performances are generally polyphonic, making it much more difficult to analyze individual voices than if the voices can be studied in isolation.
This thesis approaches the problem of polyphony head on, using a time-aligned electronic score to guide estimation of the vocal line characteristics. First, the exact fundamental frequency track for the voice is estimated using the score notes as guides. Next, the harmonic strengths are estimated using the fundamental frequency information. Third, estimates in notes are automatically validated or discarded based on characteristics of the frequency tracks. Lastly, good harmonic estimates are smoothed across time in order to improve the harmonic strength estimates.
These final harmonic estimates, along with the fundamental frequency track estimates, parameterize the essential characteristics of what we hear in singers' voices. To explore the potential power of this parameterization, the algorithms are applied to a real data set consisting of five sopranos singing six arias. Vowel modification and evidence for the singer's formant are explored.
Audio demos from my work
As mentioned in the abstract, my thesis starts with a polyphonic recording, such as:
and a time-aligned midi file for the singer: Using the aligned midi file as a guide, the algorithm searches for the exact frequency the soprano is singing at any given time: The harmonic strengths of the singer's voice are then estimated: As you can hear, there's definitely some noise in both the frequency estimates and the harmonic strength estimates. The sustained, loud notes seem to be estimated better than some of the shorter, quieter notes. My thesis outlines a way of finding these particularly well captured notes and then smoothing them further to remove noise and get a clean estimate for the characteristics of the vowel being sung. For this next synthesis, I have replaced the vowels in glory ("The sun whose rays are all ablaze with ever living glory ...") and 'o' in story ("... does not deny his majesty, he scorns to tell a story.") with the smoothed estimates. You have may difficulty hearing the difference without headphones, but the smoothing does make quite a bit of difference to the underlying data. So that, in a nutshell, is my thesis. These smoothed vowels can be characterized very nicely with a few parameters, which means they can be used to compare different vowels, the same vowel on different pitches, and the same vowel sung by different singers. For example, the following image shows the harmonic gains (red stars) for the vowel "AA" (as in father) calculated from multiple notes sung by the soprano lead in a recording of H.M.S. Pinafore (this is figure 9.2 in my thesis):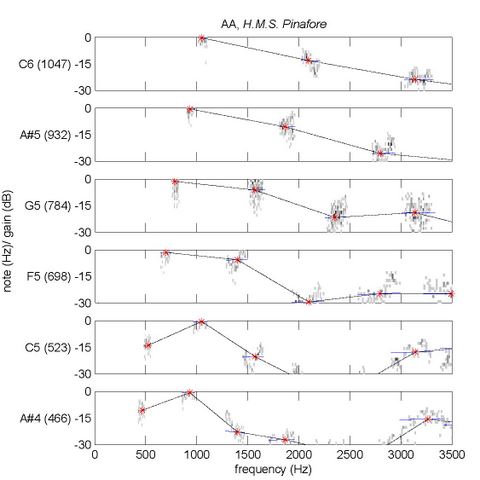
What makes this particularly cool is that all this information is coming from polyphonic recording, which hasn't really been done before.