
Of Puzzles and Pieces…
The goal of the DARPA Shredder Challenge 2011 was to “identify and assess potential capabilities” dealing with sensitive information subjected to various shredding modalities. The participants of the Challenge were charged with recovering document(s) from scanned shreds and solving a puzzle presented in the reconstruction by answering a series of questions. For each puzzle of increasing difficulty, competitors are not told the number of documents or the document theme, and may also be presented with extraneous or an incomplete number of shreds.

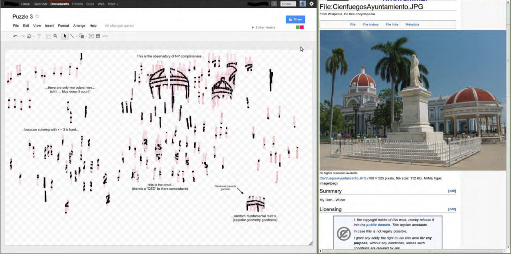
Our "Honorable Mention" Submission for Puzzle #3. Puzzle #3 Shreds.
In Puzzle #3, after partially recovering a picture depicting a location, we started to search for potential geographic matches via search engines using human scene understanding. We identified keywords related to the objects on the picture, including "palm tree," "building," "dome," "turrets," and the names of tropical countries. Try using Google Image Search with "turrets building cuba"!
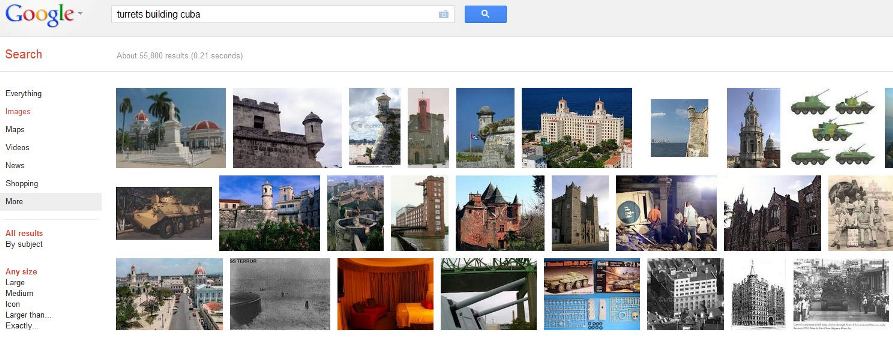
Results of a Google Image Search of "turrets building cuba."
Getting Started
Our team applied a range of techniques to solve the puzzles manually, computationally, and using a combination. While we were busy developing our algorithms, we also began solving the first puzzle by manual assembly. Print, cut, and assemble. It was not long before we jettisoned this tedious approach.
We pursue a human-machine collaborative solution to combine the best from users and automated techniques. HUMan INTelligence is a strong informant and validator to both the puzzle solving and document assembly challenges. Tools derived from information retrieval, computer vision, and machine learning were the basis for supporting our quick and accurate solutions.

Puzzle #1 Shreds.
Document Assembly
We began with a simple preprocessing of each scanned page using simple thresholding methods to remove the background and artifacts, then segment each fragment. We overlaid an alpha layer on each fragment to facilitate smooth merging.
 |
 |
 |
 |
 |
| Original Image | Line Detection | Stroke | Contour | Stroke End Point |
Our algorithmic approach for document assembly seeks to take these extracted fragments, represent them through noise and rotation invariant descriptors, and generate strong matching scores for adjacent fragments.
Fragment Features
Several fragment features informed our matching analysis, including:
- fragment orientation and relative location
- pre-print line inference
- stroke angle, width and relative location
- fragment background color
We also extracted and tested several features associated with the shapes of fragment edges, but did not find them useful. We conjecture this was due to the homogeneity of the shapes and the often severe distortion caused during the cutting process.
In the spirit of human-machine collaboration, we applied human OCR to tag each fragment with potential characters each may contain. For example, a shred may be tagged with “o” or “c” labels if it contained strokes that resembled portions of the respective characters. The human OCR tags are then leveraged in our semi-automatic query process.
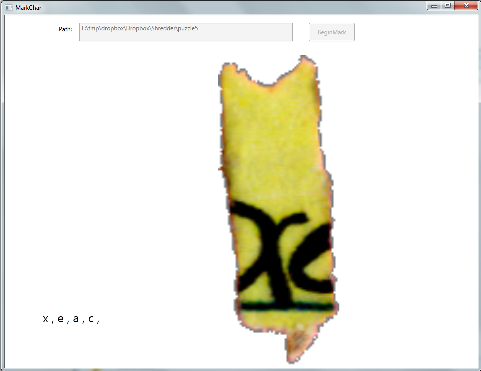
Human OCR Tool.
 Fragments with Letter “P” .
Fragments with Letter “P” .

Fragments with Letter “P” and “S”.
Interactive Query Interfaces
We developed several interfaces for users to interact with our automatic ranking systems. Users initially collaborated using these tools and a MS PowerPoint environment, but we eventually moved to a Google Document Drawing canvas.
In one match suggestion tool, the user selects a fragment from the pool of the partially assembled super-fragments to query the system. The system measures the matching score from the query and returns the most likely matching candidates one-by-one in their predicted alignment positions and orientations. This matching score is computed by agglomerating the fragment features and incorporating contextual cues. Upon visualizing the machine’s predicted matches and alignments, the user validates the results and decides whether to accept the proposed assembly.
Interactive Query Interface Fragment Matching
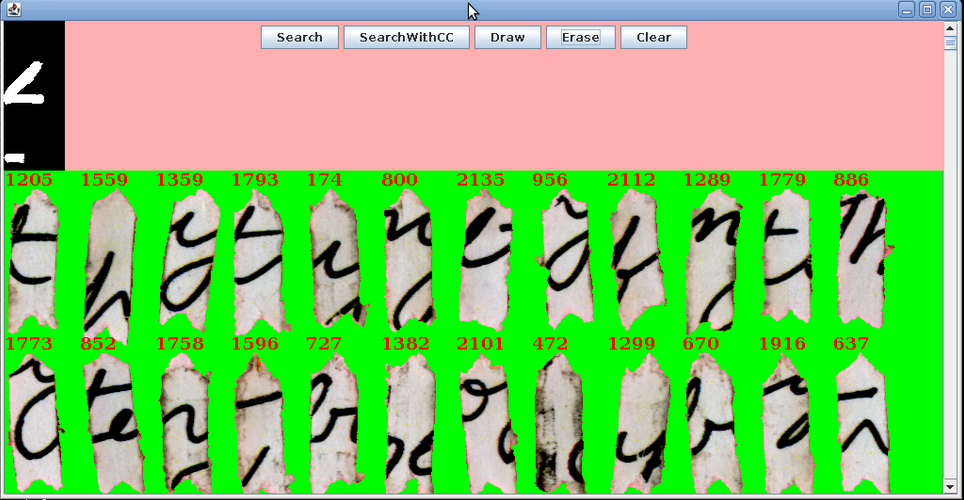
In another tool, we developed a stroke-search tool that enables users to draw in-part or in-full patterns they expect to find on potential fragment matches. This is equivalent to asking users to hand-draw the strokes expected in missing sections. A touchpad-enabled query environment also afforded us an intuitive drawing interface. The search for these drawn image queries is executed by template matching algorithms.
Touchpad Stroke Query. |
|
Three-Stroke Match Example. |


Future Work
There are many modalities that we look forward to improving toward this interesting research challenge. We are excited about the prospect of incorporating relevance feedback, active learning, and improved matching by distance metrics learning. There also a number of extensions that we expect to study in the future including dealing with noisy data toward the automated extraction of document-relevant shreds from a copious set, suggesting optimal starting points, and creative ways of leveraging human input in conjunction with rich resources on the Web (e.g. image search via partial drawing queries or semantic coupling as in Puzzle #3).
For related research topics, please visit our research site here.