20 Questions Problem in Multi-Label Image Classification

Introduction
Exploding amounts of multimedia data increasingly require automatic indexing and classification, e.g. training classifiers to produce high-level features, or semantic concepts, chosen to represent image content, like car, person, etc. Under the framework of automatic semantic concept detection, given an input image, we want the machine to automatically predict the occurrences of a set of pre-defined concepts like people, car, outdoor, wedding etc. in this image. A general approach for this multi-label classification problem can be summaried in the figure below, where individual concept detectors are trained in the one-vs.-all manner for detecting individual concepts.
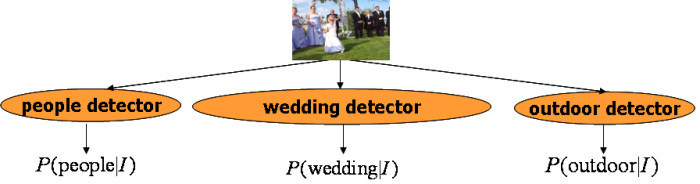
A '20 Questions' Formulation
Although automatic classification purely based on machine is interesting and desirable, the gap between low-level visual features and high-level semantic concepts remains untackled resulting in great limitation in the detection performance. A tradeoff approach, semi-automatic semantic concept classification which incorporates users' interaction, may provide a good chance for getting promising performance.
The figure below illustrates our semi-automatic semantic concept detection framework, which we call the 20 Questions Problem in multi-label image classification. Assume that some user is available so that for each given image he/she is willing to answer one or a few simple questions, e.g., whether the image is outdoor image or whether the image contains person. From the user's answer, some ground-truth information (assume that the user always provides correct answers to the questions) can be obtained regarding the occurrence of some semantic concepts in the image. Such information can be utilized to help detect the existance of the rest concepts.
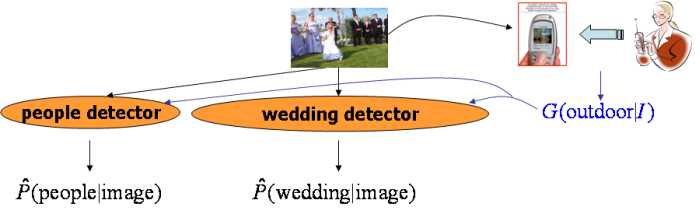
Interesting Topics
There are many interesting issues to explore under above semi-automatic framework. For example, how to model the relationship among different semantic concepts so that the ground-truth information for some concepts can help detect others. Also, since the user can only label one or a few concepts, which concepts should the system actively select for the user to label so as to optimally help detect the rest concepts.
A Tentative Approach
We propose an active context-based concept fusion algorithm. We solicit users' answers for a few simple yes/no questions, e.g., whether the image contains people or not. The annotations are used as ground-truth information to refine the detection of the rest of concepts. We use information theoretic criteria to automatically determine the optimal concepts for user to annotate. In addition, we have developed an effective method to predict concepts that may benefit from context-based fusion. Please refer to the reference below for more details if you are interested.
People
Publication
-
Wei Jiang, Shih-Fu Chang, Alexander C. Loui. Active Context-based concept fusion with partial user labels. In IEEE International Conference on Image Processing (ICIP 06), Atlanta, GA, USA, 2006. [pdf]
For problems or questions
regarding this web site contact The
Web Master.
Last updated: Jan 25th, 2009.