Automatic Discovery of Query-Class-Dependent Models for Multimodal Search

Summary

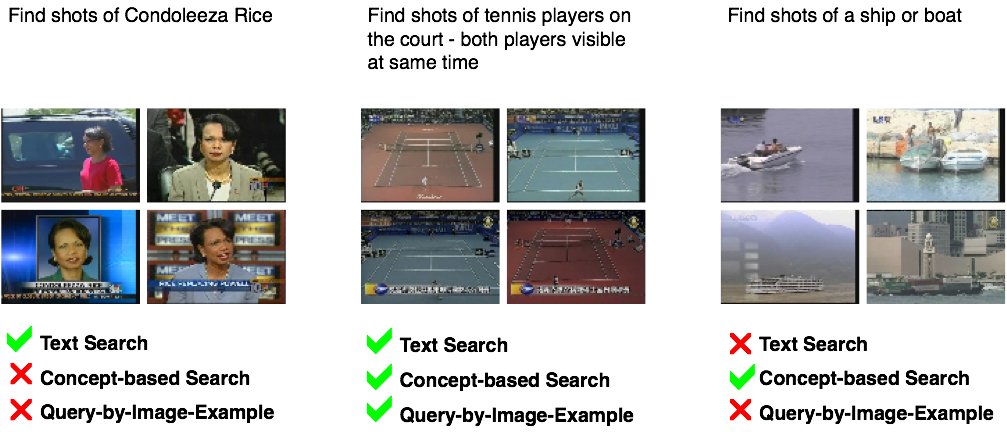
In many search applications, there are cues available from a variety of information sources. In broadcast news video databases, this information might be conveyed through the visual content of the video image, the timing and pitch of the news anchor's speech, and the closed caption transcript of words being spoken. In search, the task is then to appropriately utilize all of these various cues to best answer the query. In typical systems, various methods are developed to search each cue separately (like a query-by-example image search for the visual modality and a keyword text search over the text transcripts) and then to combine the results. It quickly becomes apparent that different queries see different levels of success resulting from various single-modality searches. A search for a named person might fair better using only text keywords, while sports-related queries might benefit most from an example query image. Some example queries and the likelihood of success for various search methods are shown in the figure below. Clearly, we need a mechanism for adapting the search approach according to the query. One such approach that has been proposed is to define "classes" of queries, where queries within each class benefit from similar search approaches. Incoming queries can then be classified into one of these query classes and the according strategy can be applied. The problem with this approach is that it is difficult for humans to manually define such classes. We therefore propose to use collections of queries (with known relevance labels in the search set) to automatically learn classes of queries and the optimal models for each query.
Performance and Semantic Space
What criteria should we use when forming classes of queries? There are two constraints to consider here. On the one hand, it is intuitive that the classes of queries should rely on similar search methods: we expect that queries will have strong performance from some individual search methods and weak performance among others and that this should be consistent among queries within any given class. On the other hand, when we have an incoming query, all we have is few keywords or example images that the searcher has provided. We do not know the relative performance of each of the search methods, so we cannot find the class of queries with similar performances. We can only find queries with similar keywords or examples.
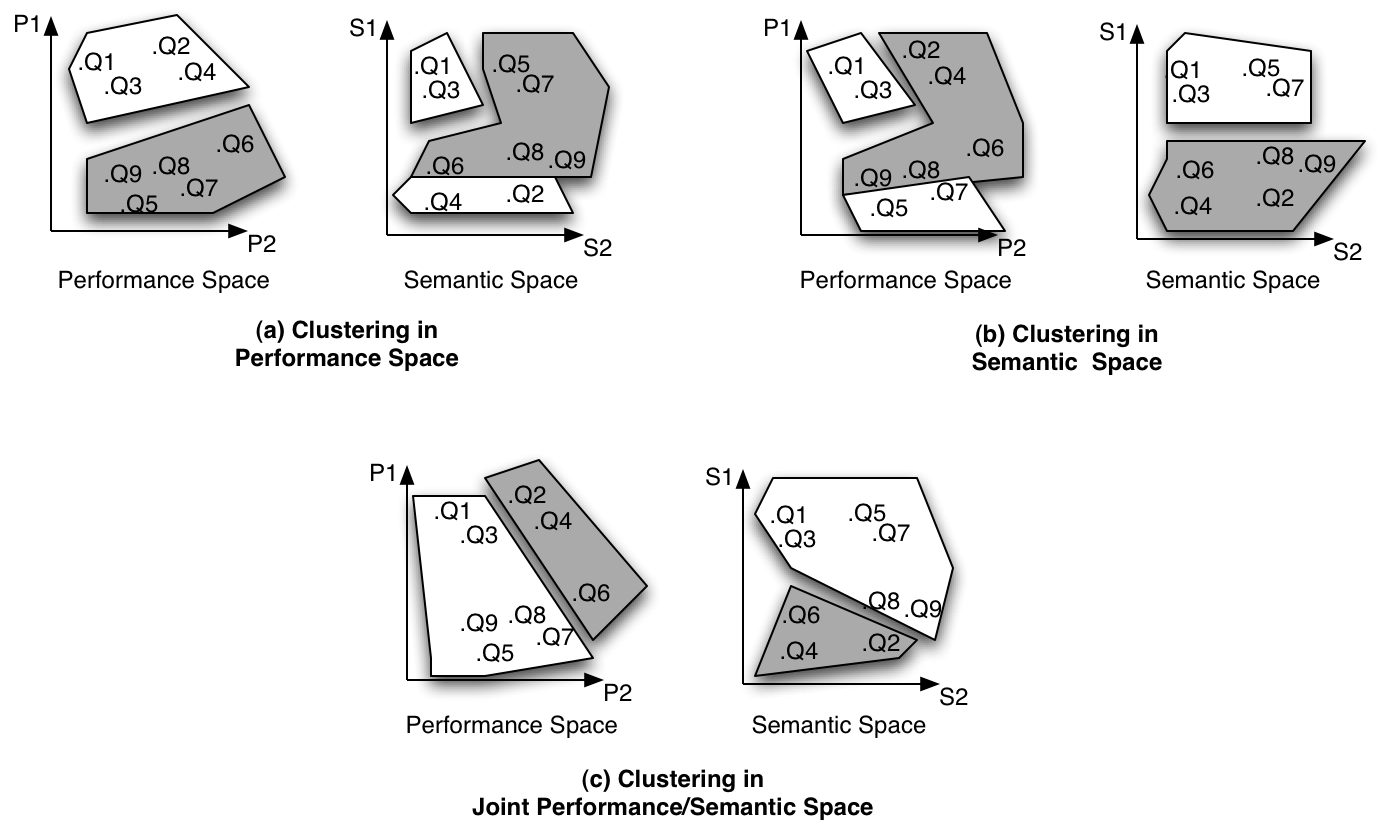
We can view these two measures of the query as two separate spaces in which the query can reside. We call the performance of the various search methods the "performance space" and we call the content of the query the "semantic space." We aim to discover classes of queries by placing some example queries in these spaces and conducting clustering, taking the resulting clusters to be the query classes. In the figure below, we show nine hypothetical queries mapped into both performance and semantic spaces. In figure (a), we show the results of clustering in only performance space. In this case, the resulting clusters are similar in terms of performance, but the cluster is split in terms of semantics. This will make it hard to map new queries into the correct class at query time. Similarly, in figure (b), we show the results of clustering in semantic space alone. The resulting clusters are well-formed in semantic space, so they will be easy to map new queries into at search time, but the performance space is ill-formed, so the resulting query classes might not even share appropriate search models. Our solution is shown in figure (c), where we cluster in both performance and semantic space simultaneously and we end up with clusters that are well-formed in both spaces, meaning that they will result in classes with similar search models and that new queries can easily be placed into the correct class.
Experiments and Results
We apply the model to the TRECVID automatic search task. We construct a performance space for the queries by developing several different search methods, including a text-based keyword search, a query-by-example image search, and various query expansion approaches. The perfomance space is explicitly the performance of each of the methods for the given query, measured in average precision. We construct the semantic space by extracting various pieces of information about the query, such as the occurrence of various types of named entities (such as people or locations), and the counts of various parts of speech, like nouns and verbs. We generate a set of roughly 100 queries with known relevance labels to construct the classes and we then apply the method to the TRECVID 2004 automatic search task. We compare the method against a query-independent approach (with no classes) and other query-class-dependent approaches with human-defined query classes. We confirm that query-class-dependency can significantly improve the performance of multimodal search and we further find that automatically-discovered query classes can outperform human-defined ones.
We further investigate the resulting classes by looking at some of the queries that the various classes contain. In the figure below, we show some examples from six of the discovered classes. On the left we show the relative performance of the queries in each of the individual search methods (Speech transcript, Pseudo-relevance feedback, WordNet expansion, Google expansion, Image, and Person-X). In each class, we see a tendency to rely on similar search methods. We also see that some of the classes are easily identified semantically. The first one is clearly name persons. The second is named locations. The third contains logos. Some of the classes are strange combinations of semantically distinct topics that nonetheless share similar search strategies. The fourth class, for example, seems to merge vehicles and sports. The fifth class is animals, but contains others as well. Finally, some classes are formed very strongly around the performances space, such as the sixth class, which exhibits strong performance from the image search approach, but it is unclear what the common semantics are.

People
![]()
Publication
![]()
- Lyndon Kennedy, Paul Natsev, Shih-Fu Chang. Automatic Discovery of Query Class Dependent Models for Multimodal Search. In ACM Multimedia, Singapore, November 2005. [pdf]
For problems or questions
regarding this web site contact The
Web Master.
Last updated: Sept. 30th, 2008.