Tracing the Manipulation Histories of Photographs on the Web

Summary

We have observed that many popular images on the web are frequently copied, manipulated, and re-posted by many different web authors. This aggregate behavior essentially gives rise to a "family tree" for a given image, where parent-child relationships emerge from having a child image derived from the parent through some editing action. The emergent structure of this family tree, which we call a visual migration map (VMM) can have a number of interesting attributes. The top-most node might be the closest to the original version of the image. The leaf nodes, with high amounts of visual manipulation, might have completely divergent content, which might change the meaning of the original image or the perspective that it conveys. We propose that many of these image editing actions leave artifacts in the visual content of the image that can be used as cues to infer if a parent-child relationship might exist between any two images and to automatically extract an approximation of the image editing history across a plurality of examples of a given image.
Visual Migration Maps
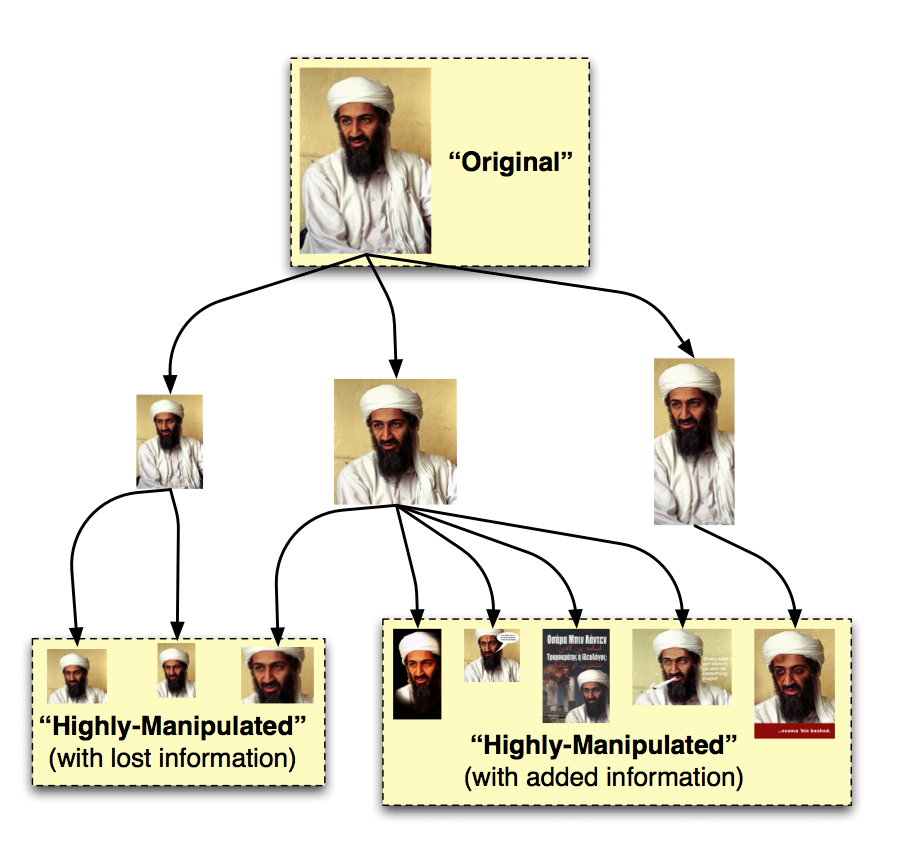
In the figure below, we show an example of what a visual migration map might look like for a given image. Here, each particular image within the graph would represent an instance of the image that a user on the web has created. The edges between the images imply a parent-child relationship between the two images: the child was derived from the parent through a series of visual manipulations. At the top of the graph, we see the highest-resolution image with the largest crop area, which is most likely the closest to the original instance of the image, from which all other images are descended. At the bottom-right, we see some highly-manipulated versions of the image where external information has been overlayed on the original content. These may be of interest, since their content is highly divergent from the original image and they may represent subversions of the viewpoint conveyed by the original. At the bottom-left, we see other highly-manipulated versions of the image, where information was only removed from the original (either by scaling-down or by cropping). These may instances be of much less interest.
Automatically Constructing Image Histories
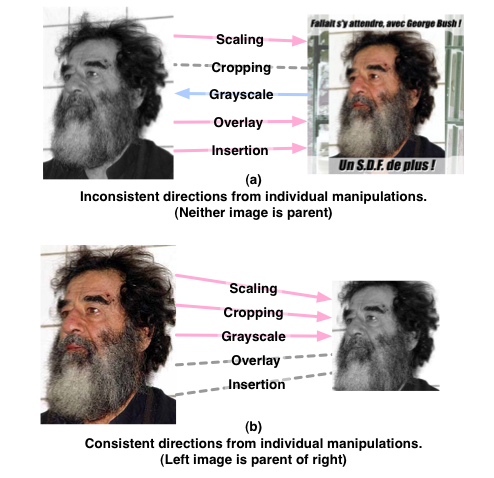
We propose that it is infeasible to ever create a true visual migration map for any given image, since, without the specific knowledge of image sources and manipulations provided by the image author, we can never definitively know the parent-child relationship (or if one even exists) between any two images. We do suggest, however, that aspects of the visual content of images can provide important cues about the parent-child relationships between images and that, specifically, certain contradictions in the visual content can lead us to definitively state that it is impossible that certain image pairs have parent-child relationships and that it is plausible that these relationships exist between other pairs. We propose that many types of image manipulations imply a directionality between the two images. Some examples of these manipulations are shown in the figure below. The manipulations are defined as follows. Scaling is the creation of a smaller, lower-resolution version of the image by decimating the larger image. In general, the smaller-scale image is assumed to be derived from the larger-scale image, as this usually results in preservation of image quality. Cropping is the creation of a new image out of a subsection of the original image. The image with the smaller crop area is assumed to have been derived from the image with the larger crop area. Grayscale is the removal of color from an image. We generally assume that the grayscale images are derived from color images. Overlay is the addition of text information or some segment of an external image on top of the original image. It is generally assumed that the image containing the overlay is derived from an image where the overlay is absent. Insertion is the process of inserting the image inside of another image. Typical examples might be creating an image with two distinct images placed side by side or by inserting the image in some border with additional external information. It is assumed that the image resulting from the insertion is derived from the other image. Of course, there are exceptions in the directions of each of these manipulations: it is possible, though not ideal, to scale images up, or an overlay could be removed with retouching software. Still, we assume the directions that we have specified are true in most cases.

Once we have the knowledge of the implied directionality of each of these edits, we can then check whether or not they tell a consistent story. If one edit type implies that image A is derived from image B and another edit type implies just the opposite, then it is highly unlikely that any parent-child relationship exists at all. If all of the edit types agree, then it is plausible that the parent-child relationship is actually true. The figure below shows examples of cases where these edits are either consistent or inconsistent.
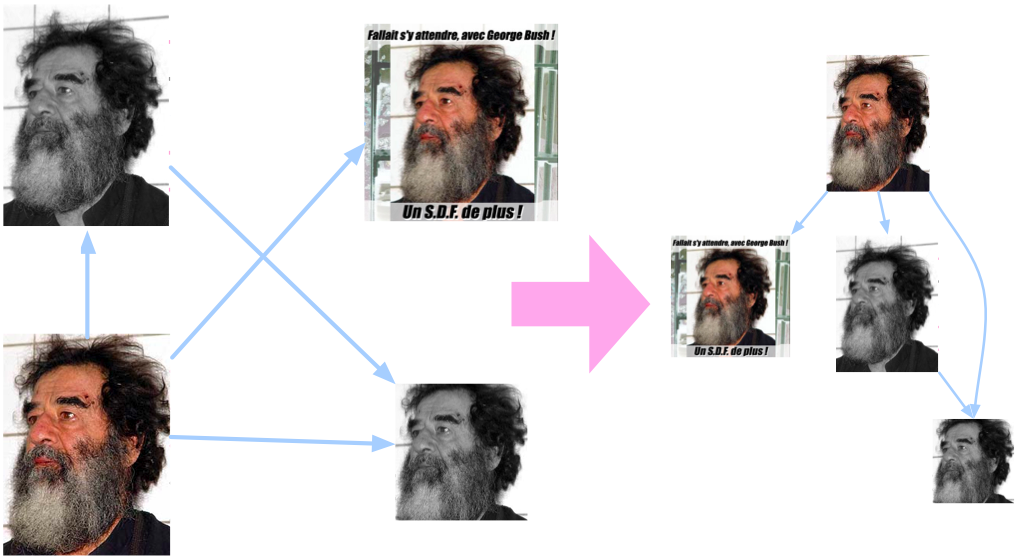
The resulting parent-child relationship decisions across a plurality of examples of the image will then give rise to a graph structure, which is the automatically-constructed visual migration map. The following figure demonstrates how these pair-wise cues across the four example images above result in a visual migration map.
Experiments and Applications
We apply the above-described approach to images crawled from the web. Given a set of images that are found to be copies of each other, we automatically detect each of the parent-child relationships between each pair of images and arrive and an automatically-generated visual migration map. We apply the approach to 22 image sets related to political figures and find that the emerging automatically-detected migration maps are highly similar to migration maps generated through human annotations. An example of one such automatic map is shown below.
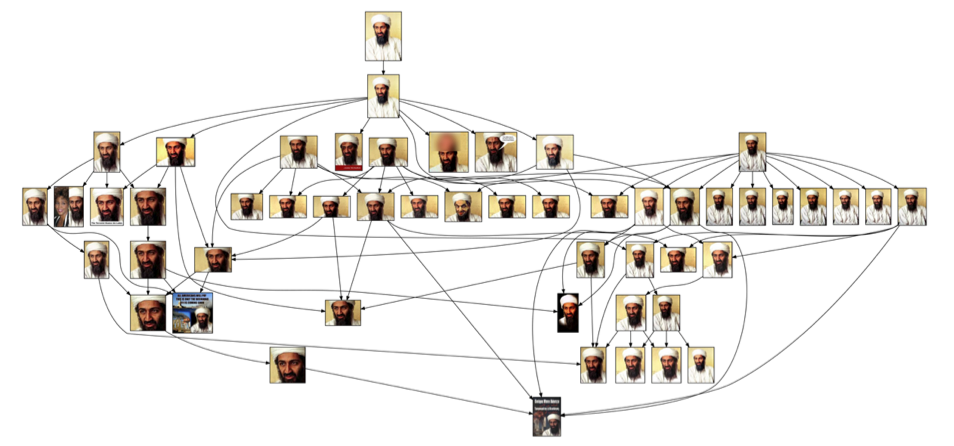
We see that despite some errors in the detection of edits and parent-child relationships, the overall structure of the graph is similar to what we would like. Particularly, the parent node is similar to the original image in that it has the highest resolution and largest crop area. We also see that the interesting highly-manipulated images are all located on sink nodes. Below, we show some example results of finding the most original and most manipulated images directly from these visual migration maps.

We further explore the results by manually labeling each of the images as either being highly-manipulated or original and then also exploring the webpages that originally referenced the images and label the ideological viewpoint of the webpage as being either positive, neutral, or negative with respect to the image. We observe that, indeed, there is a correlation between the addition of high degrees of manipulation and the subversion of the meaning of viewpoint conveyed by an image. Some examples of these correlations are shown in the figure below.

Acknowledgment
This material is based upon work supported by the National Science Foundation under
Grant No. 0716203. Any opinions, findings, and conclusions or recommendations expressed
in this material are those of the author(s) and do not necessarily reflect the views
of the National Science Foundation.
People
![]()
Publication
![]()
-
Lyndon Kennedy, Shih-Fu Chang. Internet Image Archaeology: Automatically Tracing the Manipulation Histories of Images on the Web. ACM Multimedia 2008, Vancouver, Canada, October 2008. [pdf]
For problems or questions regarding
this web site contact The Web Master.
Last updated: May 15th, 2008.