| DVMM / Research / VideoMining | |||
Video Mining and Spatial-Temporal Pattern Discovery |
|||
| Overview | |||
| Organizing multimedia content with as few labeled examples as possible is a problem of both theoretical and practical interest. This work is concerned with unsupervised learning of temporal structures, i.e., finding a statistical description for similar repetitive segments and locating them from the original sequences simultaneously. Example interesting structures include: large camera motion followed by audience cheering in sports highlights, or dubious human motion co-occurring with sound spotted by a surveillance setup. We approach the problem in two aspects: (1) Discovery of video structure by unsupervised learning -- our current solution involves the use of dynamic graphical models with automatic adaptation of the model size and the feature set; (2) Associating meanings to discovered structures using the metadata streams -- our current approach involves co-occurrence analysis between the identified structures and speech transcript and refining the co-occurrence statistics with machine translation techniques. Future investigations would focus on multimodal fusion, scalability at different semantic levels, applications to multimedia retrieval etc. | |||
| Part I | 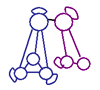 |
Unsupervised Disocovery of Video Structure with Statistical Temporal Models This part of the work presents: a computational framework for modeling the recurrent temporal events in diverse domains [icme03, VideoMining03]; and algorithms automatic grouping of content descriptors for the relevant set of events [icip03]. |
|
| Part II | 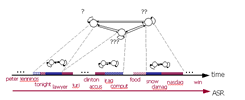 |
Finding Meaningful Video Structure in News with Associated Text This part is concerned with automatic association of semantic meanings to the large set of temporal structures discovered [icip04]. |
|
| Part III | 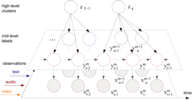 |
Layered Dynamic Mixture Model for Multimodal Pattern Discovery across Asynchronous Streams This part is concerned with inferring frequent patterns from the joint statistics of a set of streams of different information rate, e.g. audio, video and text. |
|
| Prospective extension |  |
Multi-stream Temporal Event Mining in AV Sensor Surveillance System The generalized pattern mining problem in un-edited, distributed multi-sensor system. |
|
| Preparation |  |
Structure Parsing for Sports Videos Using Hidden Markov Models The unsupervised leanring framework in part I has been evaluated on various sports videos where the results coincide with the domain insights obtained from supervised learning techniques [icassp02, prletter04]. |
|
| Publications and Reports | |||
| See the list of publications on the publications page, and a set of overview slides here. | |||
| People | |||
| Last update: October 6, 2004 | |||