| ~ Lexing Xie / Research / VideoMining / Part III | |
Multimodal Fusion in Asynchronous Streams |
|
| Abstract | |
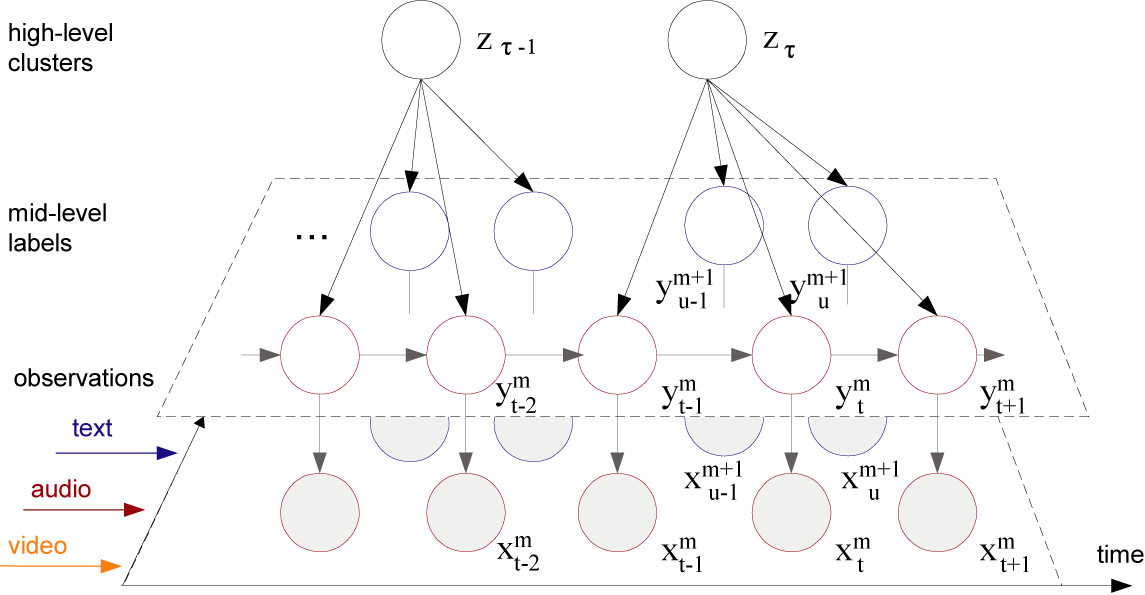
| We propose a layered dynamic mixture model for asynchronous multi-modal fusion for unsupervised pattern discovery in video. The lower layer of the model uses generative temporal structures such as a hierarchical hidden Markov model to convert the audio-visual streams into mid-level labels, it also models the correlations in text with probabilistic latent semantic analysis. The upper layer fuses the statistical evidence across diverse modalities with a flexible meta-mixture model that assumes loose temporal correspondence. Evaluation on a large news database shows that multi-modal clusters have better correspondence to news topics than audio-visual clusters alone; novel analysis techniques suggest that meaningful clusters occur when the prediction of salient features by the model concurs with those shown in the story clusters. | |
 |
|
| Publications and Reports | |
| L. Xie, L. Kennedy, S.-F. Chang, A. Divakaran,
H. Sun, C.-Y. Lin (2004). "Layered Dynamic Mixture Model for Multimodal
Pattern Discovery across Asynchronous Streams." DVMM Technical Report, 2004. |
|
| Last update: October 6, 2004 | |