![]()
Automatic Feature Discovery in Video Story Segmentation

Summary

News story segmentation is an important underlying technology for information exploitation in news video, which is a major information source in the modern era. In our prior work, we demonstrated statistical approaches for fusing diverse multimodal features (e.g., motion, face, prosody, etc.) in terms of feature selection (induction) and classification among sets of mid-level perceptual features. Though promising, these mid-level perceptual features are typically manually selected relying on expert knowledge of the application domain.
In this project, we propose an information-theoretic framework, to automatically discover adequate mid-level features – semantic-consistent clusters. The problem is posed as mutual information maximization, through which optimal cue clusters are discovered to preserve the highest information about the semantic labels. We extend the Information Bottleneck (IB) framework to high-dimensional continuous features to locate these semantic-consistent clusters as a new mid-level representation, as shown in the following figure. The biggest advantage of the proposed approach is to remove the dependence on the manual process of choosing mid-level representations and the huge labor cost involved in annotating the training corpus for training a detector for each mid-level feature.
We test the proposed framework and methods in story segmentation of news video using the corpus from TRECVID 2004. The proposed approach achieves promising performance gain over representations derived from conventional clustering techniques and even the mid-level features selected manually. It is the first work to remove the dependence on the manual process in choosing the mid-level visual features and the huge labor cost
involved in annotating the training corpus for training the detector of each mid-level feature. Meanwhile, it is one
of the best approaches for story segmentation in TRECVID 2004 and is effectively extendable to new video sources and the only international video story boundary provider in TRECVID 2005 and 2006.
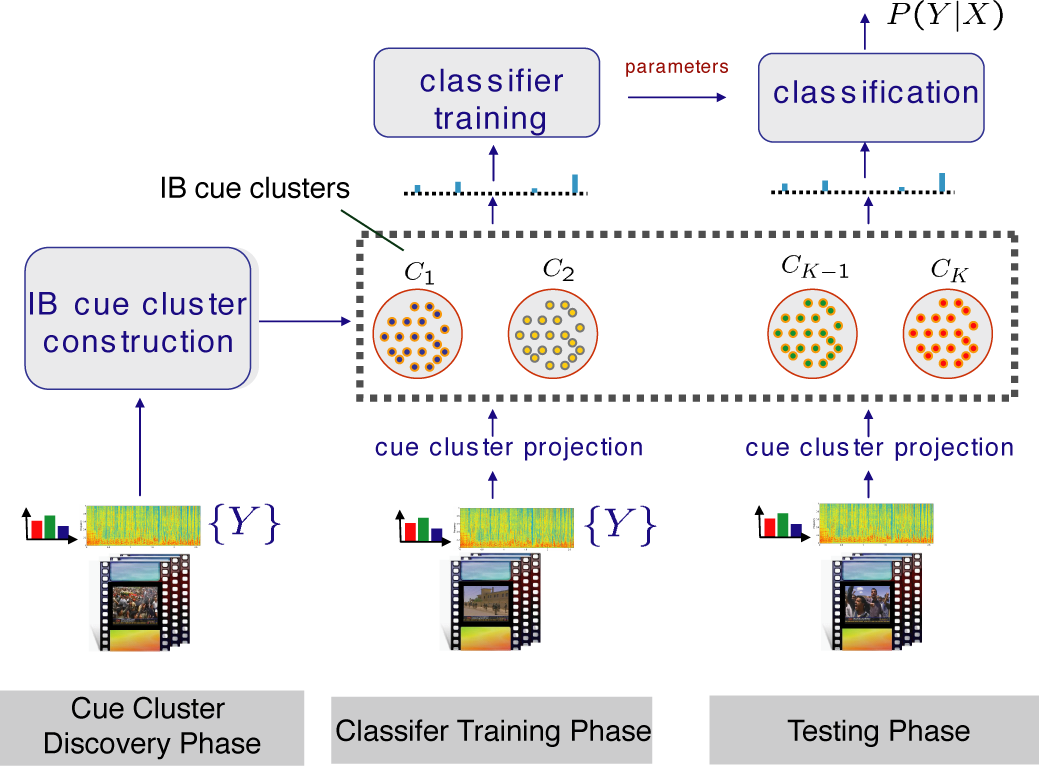
| The illustration of automatic story boundary detection task based on automatically discovered visual cue clusters (mid-level features). It includes three major phases, cue cluster discovery, classifier training, and testing. |
People
Publication
Winston H. Hsu and Shih-Fu Chang, "Visual Cue Cluster Construction via Information Bottleneck Principle and Kernel Density Estimation," The 4th International Conference on Image and Video Retrieval (CIVR), Singapore, July 20-22, 2005. (PDF)
Winston H. Hsu, Lyndon Kennedy, Shih-Fu Chang, Martin Franz, and John Smith, "Columbia-IBM News Video Story Segmentation In TRECVID 2004," Columbia ADVENT Technical Report 209-2005-3, New York 2005.
(PDF)
Link
- Broadcast News Video Story Boundary Detection in TRECVID 2005/2006
- NIST TREC Video Evaluation Project
![]()
For problems or questions
regarding this web site contact The
Web Master.
Last updated: January 10, 2007.