
Columbia
University at TRECVID 2006:
Semantic Visual Concept Detection and Video Search

Summary

We participated in NIST TRECVID 2006 video retrieval evaluation, focusing on the areas of visual concept detection and integrated search. Our objectives are to investigate the effectiveness of individual indexing and retrieval components and their impact on the overall user experience in video retrieval. We have incorporated some of our latest research results in semantic concept detection (particularly when applied to many hundreds of concepts) and multimodal retrieval.
TRECVID is an open forum for encouraging and evaluating new research in video retrieval. It features a benchmark activity sponsored annually, since 2001, by the National Institute of Standards and Technology (NIST). In 2006, the evaluation included four tasks: shot boundary detection, high-level feature (concept) detection, search, and stock footage exploration. The data set for TRECVID 2006 was greatly expanded over previous years, including more than 160 hours of broadcast news video from 6 different channels in 3 different languages. The evaluation attracted more than 60 groups from around the world, resulting in very informative outcomes in assessing the state of the art and exchanging new ideas. More details about the evaluation procedures and outcomes can be found at the NIST TRECVID site.
Columbia's DVMM team participated in TRECVID 2006 evaluation for the high-level feature (concept) detection and search tasks. We also collaborated with IBM Research and AT&T Research in evaluating new methods for different tasks mentioned above.
High-Level Feature Extraction (Concept Detection)
In TRECVID 2006, we explore several novel approaches to help detect high-level concepts, including the context-based concept fusion method that incorporates inter-conceptual relationships to help detect individual concepts; the lexicon-spatial pyramid matching method that adopts pyramid matching with local features, event detection with Earth Mover’s distance that utilizes the information from multiple frames within one shot for concept detection, and text features from speech recognition and machine translation to enhance visual concept detection. In the end, we find that each of these components provides significant performance improvement for at least some, if not all, concepts. The overall framework in which all of these methods are applied is shown in the figure below. Each of the unique methods is discussed further in the following section.
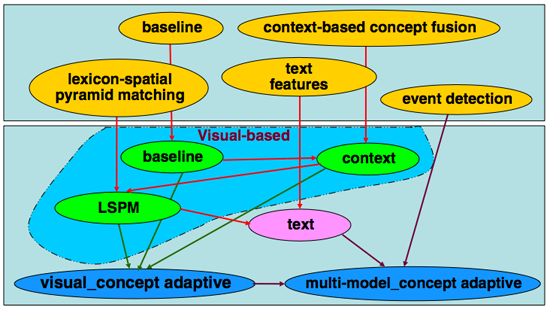
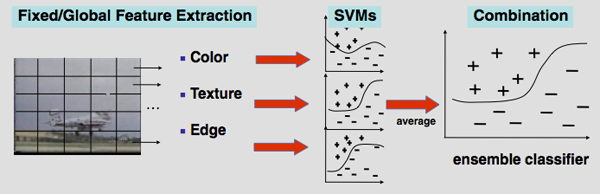
Baseline Concept Detection [5]
The entire concept detection framework stands on top of a robust baseline concept detection system, shown in the following figure. This system is lightweight, relying on only three types of low-level features and provides strong performance. Each of the three low-level feature types is extracted from a single keyframe for each video shot: color moments on a 5x5 grid, Gabor textures across the entire image, and an edge direction histogram on the global image. Individual support vector machine (SVM) classifiers are then trained on each of the three feature spaces, giving three different classifications of the test shots. A final, fused baseline score for each of the shots is determined by simply averaging the scores resulting from each of the low-level feature sets. We deliberately choose such a generic method for the baseline, since similar approaches have been repeatedly shown to be strong and since the method is fast enough to be applied to a large set of 374 concepts, which is far beyond the 39 required for the TRECVID evaluation. These 374 concepts are selected from the 449 LSCOM concepts, based on the number of positive training examples available. (Roughly 75 concepts have too few examples to build a reliable detector). This rich set of hundreds of concept detectors can be leveraged to improve concept detection on individual concepts and to help in search, as we will demonstrate later.
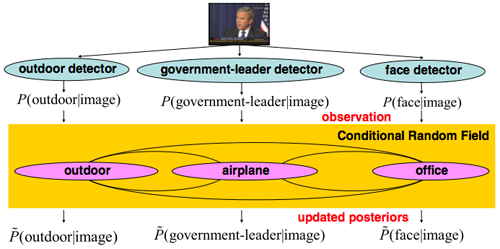
Context-based Concept Fusion [6]
With context-based concept fusion, we can leverage the large set of 374 concepts detected using the baseline method to provide context for individual concept detectors and to help refine the results. The figure below shows a general framework for the context-based concept fusion framework. Generally, the method works by taking initial baseline concept detection scores and mining the interrelationships between concepts. For example, the "government-leader" concept often occurs in the same frame as "flag-us" and "face" and rarely occurs in the same frame as "sports." So, this knowledge of contextual relationships and the baseline scores for each of these concepts can be leveraged to refine the original detector. These relationships between concepts are modeled with a conditional random field (CRF) and each node in the model represents a concept, while edges represent relationships between concepts. Detection scores of 374 LSCOM concepts generated by the baseline detectors are taken as input observations. Through iterative learning, the detection results for each of the target concepts are refined. The joint conditional posterior probabilities of class labels are iteratively learned by the well-known Real AdaBoost algorithm. Context-based concept fusion has been shown to have variable performance: for some concepts it provides large gains, and for other it can degrade performance. To address this, we propose a method for predicting when the context-based concept fusion method will provide improvement, based on the performance of the baseline detector on a validation set and the degree of correlation found with other concepts. Through this approach, we predict 16 concepts to apply the framework to. Four of those 16 concepts are formally evaluated in TRECVID 2006. Three of the concepts show significant improvement and the other shows no change.
Lexical-Spatial Pyramid Match Kernel
Each of the above-mentioned methods is so-far reliant only on global or grid-level features from a still keyframe to detect visual concepts. The Lexical-Spatial Pyramid Match Kernel, however, applies SIFT features to utilize local and spatial information to enhance and refine the baseline concept detectors. SIFT features are extracted locally and consist of a vector of 128 feature values for each point in an image. A typical approach to dealing with so many feature points is to quantize the features into a bag-of-words representation. The LSPM approach utilizes different vocabulary sizes (or lexicon levels) to represent images at varying lexical granularities. Similarly, matching between SIFT nag-of-words features can be done across the entire global image, or constrained to small areas based on spatial decomposition. In LSPM, many different lexical and spatial levels are used together to compute similarities between images. The net effect is an LSPM kernel which can be computed between all pairs of images and used with an SVM to detect visual concepts. This approach is used in addition to the baseline for a number of pre-selected concepts and is shown to consistently provide improvement over the baseline.
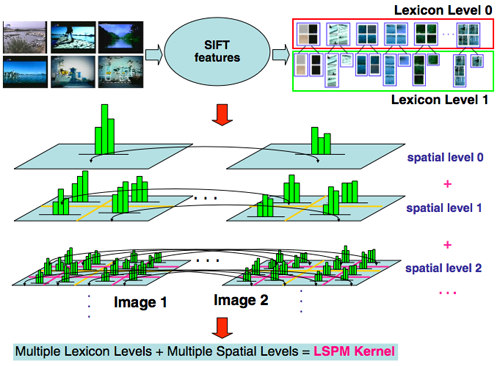
Figure: Matching SIFT bags-of-words representations
across multiple spatial levels and vocabulary sizes.
Event Detection
The above-mentioned concept detection algorithms use only the contents of a single keyframe to detect concepts in a video shot. While this approach might be adequate for many concepts which involve only static objects or scenes, events or activities with a temporal component will most likely not be adequately represented. Therefore, we propose an event detection framework (shown in the following figure) which involves feature extraction and matching of frame sequences. Each keyframe is represented by concept detection scores resulting from the baseline method described above. The distance between two shots can then be measured as a combination of the distances between two sets of keyframes. Since shots can be of varying lengths, we develop a many-to-many distance metric based on the earth mover's distance (EMD). In TRECVID 2006, only one event concept (“people marching”) is evaluated, and the event detection framework does not show significant improvement over the baseline. In our follow-up work [7], however, we have expanded the initial method by introducing multi-resolution segmentation in the temporal dimension of the videos and measure the EMD-distance among videos at multiple resolutions. Such multi-resolution matching method allows for flexible temporal alignments of video frames while preserving the proximity of neighboring frames at various scales. Our experiments over ten different event concepts confirmed the significant performance improvement of the EMD event detection method over the baseline approach.
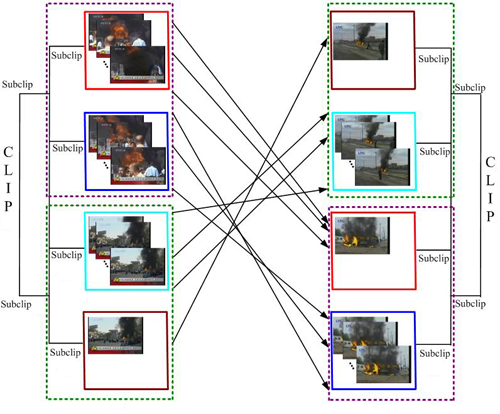
Figure: The multi-resolution EMD matching
method computes optimal temporal alignments of frames (at the finest level)
and subclips (at coarser levels). The above example shows that video events
like (“riot’) may consist of certain frames or subclips of
consistent appearances but varying temporal orders. One video includes
“flame” before “smoke”, while the other has them
reversed.
Automatic Search
The use of pre-trained concept detectors for semantic search over image and video collections has gained much attention in the TRECVID community in recent years. With the recent releases of large collections of concepts and annotations, such as the LSCOM and MediaMill sets, the TRECVID 2006 benchmark presented one of the first opportunities to evaluate the effects of using such large collections of concepts, which are orders of magnitude larger than the collections of several dozen concepts that have been available in past years. In TRECVID 2006, we specifically set out to explore the potential of using a large set of automatically detected concepts for enhancing automatic search. In particular, we explored which query topics can benefit from the use of concept detectors in the place of or in addition to generic text searches. We further explore the effects of using current large collections (374 concepts) instead of the smaller, standard set of 39 concepts. All of our submissions to TRECVID 2006 are fully automatic runs, without using manual query formulation or interactive search.
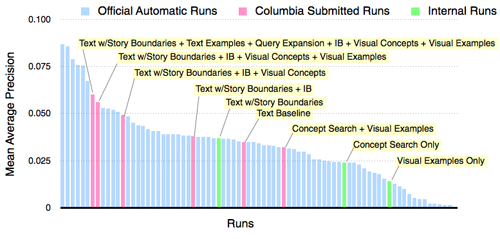
The concept search results were used in combination with many other search components, such as text search, query expansion, information bottleneck (IB) reranking [8], and visual example-based search. Results between various components were fused using a query-class-dependent fusion approach, where the weights applied to each component search method were varied depending upon the type of query. The overall search framework is shown in the following figure. Applying all of the available components resulted in an increase in performance of 70% relative to the text baseline. The use of concept detectors in the concept-based search method gave the largest improvement of any individual method, improving 30% relative to the text story baseline.

As the above figure illustrates, the multimodal search system is built upon the fusion of several independent search methods, based on the type or "class" of the query entered by the user. The core search methods are as follows:
- Text search: take text keywords provided by user and match against speech recognition transcript and machine translated output for foreign language of the news video. When text segments matching a query are found, text-based scores can be associated with neighboring shots either by propagating the scores to all shots within a fixed temporal window, or to all shots within an automatically detected news story boundary [9].
- IB reranking: mine the results of text search to find recurring visual patterns in the search set and re-order and refine results based on discovered patterns [8].
- Query expansion: use detected named entities to mine external corpora (such as web news stories from the same time frame) to uncover other meaningful search terms.
- Concept-based search: apply 374 baseline concept detectors to search set. Map text keywords to concept detector definitions and use matching detectors to rank shots in search set.
- Image search: query using a few example images provided by the user. Use Euclidean distance and SVMs to find similar shots in the search set.
These core methods are then combined with a query-class-dependent fusion framework. In this approach, the final, multimodal search score for a particular query is determined by taking a weighted summation over the core search methods. However, since different types of queries require different weightings for each of the methods, we first classify the incoming queries into pre-defined classes of queries and apply weights that are learned to be optimal for that query. The figure below shows the added performance in retrieval experienced by adding in each individual search component. We see that combining all methods used together improves over the text baseline by 70%. We also see that the single component with the largest added benefit is concept-based search, which improves over the text search baseline by 30%.
Concept-based Search
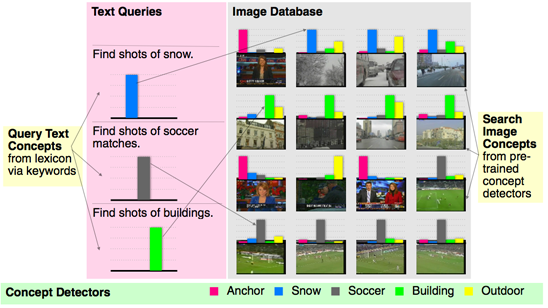
The most unique component of our multimodal search framework is the concept-based search method. This method utilizes a huge collection of 374 pre-trained concept detectors. The method works by representing both visual search documents (such as the video shots in the search corpus) and semantic query inputs (such as the text keywords contained in the search topic) in a semantic space of 374 concepts. The visual documents are mapped into this space simply according to the results of the baseline concept detectors. The textual queries are mapped into this space by matching between the query keywords and pre-defined lists of synonyms for each concept. The relevance score of each video document is then computed by fusing the detection scores of the matched concepts. The overall flow of the framework is shown in the following figure. In the figure, a lexicon of only 5 concepts is used to represent queries and images, but in our system a much larger set of 374 concepts is used.
Evaluating the Impact of 374 Concept Detectors
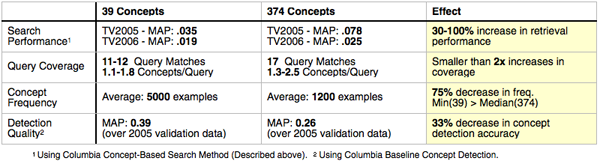
The use of 374 concept detectors is a key new approach in TRECVID 2006 and as such should be compared to a baseline method of using only the standard 39 concept detectors. We conduct this comparison by using two separate runs of the concept-based search system. In the first run, we use all 374 concept detectors and in the second, we use only 39. The results of this comparison across the 2005 and 2006 TRECVID query topics are shown in the following table. The key finding is that increasing the lexicon from 39 concepts to 374 concepts (a 1000% increase) results in only a 30-100% increase in retrieval performance. This is most likely due to bias towards the 39 concepts in the TRECVID query topics: we see that increasing the lexicon size only improves coverage of query topics by matching concept detectors by only 100%. Additionally, the LSCOM-Lite 39 concepts are not a random subset of the LSCOM 374 concepts. Indeed, they are selected to be more useful for search as well as more frequent and more detectable. We confirm these design intentions by observing that, on average, LSCOM-Lite 39 concepts have an average frequency of 5000 positive training examples per concept, while the 374 LSCOM concepts only have 1200 positive examples per concept. Furthermore, (most likely as a result of this disparity in frequency), the detectors trained for the 39 LSCOM-Lite concepts perform with mean average precision (MAP) of .39 over a validation set, while the LSCOM 374 concepts perform with a MAP of 0.26 over the same data. So, we find that increasing the size of the lexicon significantly improves the performance of concept-based search, but the magnitude of improvement (~100%) is not proportional to the increase in the concept lexicon (~1000%).
In a recent follow-up work, we have also investigated the use of the expanded set of 374 concept detectors in reranking results from initial search using other methods (e.g., text-base, image-based). Promising performance gains, up to 25%, are reported in [10].
People
in collaboration with IBM Research and AT&T Labs - Research.
Publications and Talks
-
Shih-Fu Chang, Wei Jiang, Winston Hsu, Lyndon Kennedy, Dong Xu, Akira Yanagawa, Eric Zavesky, "Columbia University TRECVID-2006 Video Search and High-Level Feature Extraction," in NIST TRECVID workshop, Gaithersburg, MD, Nov. 2006. [abstract][pdf]
-
Columbia University TRECVID 2006 Search Task [talk slide]
-
Columbia University TRECVID 2006 High-Level Feature Detection task [talk slide]
-
Poster for Columbia University News Video Search System [full-resolution pdf file][link to low-resolution]
-
(Baseline Concept Detection for 374 Concepts)
A. Yanagawa, S.-F. Chang, and W. Hsu, “Columbia University’s Baseline Detectors for 374 LSCOM Semantic Visual Concepts,” Columbia University ADVENT Technical Report #222-2006-8, March 2007. -
(Context-based Concept Fusion)
W. Jiang, S.-F. Chang, and A. C. Loui. Context-based Concept Fusion with Boosted Conditional Random Fields. In IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Hawaii, USA, April 2007. [abstract][pdf] -
(Event Detection)
D. Xu and S.-F. Chang, “Visual Event Recognition in News Video using Kernel Methods with Multi-Level Temporal Alignment,” submitted for publication. -
(Information Bottleneck Reranking)
Winston Hsu, Lyndon Kennedy, Shih-Fu Chang. Video Search Reranking via Information Bottleneck Principle. In ACM Multimedia, Santa Babara, CA, USA, 2006.[abstract][pdf] -
(Story Segmentation)
Winston Hsu, Shih-Fu Chang, “Visual Cue Cluster Construction via Information Bottleneck Principle and Kernel Density Estimation,” In International Conference on Content-Based Image and Video Retrieval (CIVR), Singapore, 2005.[abstract][pdf] Lyndon Kennedy, Shih-Fu Chang. A Reranking Approach for Context-based Concept Fusion in Video Indexing and Retrieval. Submitted for publication.
{kind=link}
Demo
Columbia News Video Search Engine (link)
Related Projects
- Large Scale Concept Ontology for Multimedia (LSCOM)
- Download: Columbia University’s Baseline Detectors for 374 LSCOM Semantic Visual Concepts
- Download: Columbia Story Boundary Data Set for TRECVID 2005
- Columbia University TRECVID 2005 Evaluation
- IBM Research TRECVID 2006 Video Retrieval Evaluation
- AT&T Research Lab TRECVID 2006 Video Retrieval Evaluation
Sponsor
DTO VACE II Program
![]()
For problems or questions
regarding this web site contact The
Web Master.
Last updated: March 5th, 2007.