Columbia EE and CS presented three papers at DAC 2016
The Columbia University Computer Engineering faculty contributed three papers to the technical program of the 53rd ACM/IEEE Design Automation Conference (DAC) in Austin, Texas. Founded in 1964, DAC is the most prestigious conference in the area of design and automation of electronic systems, and is also one of the oldest conferences in computer science. Kshitij Bhardwaj, a fourth-year PhD student, presented a paper that he wrote in collaboration with his advisor Professor Steven Nowick.
Paolo Mantovani, a fifth-year PhD student, presented a paper that is the result of an interdisciplinary collaboration between researchers in the System-Level Design Group led by Professor Luca Carloni and in the Bioelectronic Systems Lab led by Ken Shepard, who is the Lau Family Professor of Electrical Engineering at Columbia.
Carloni presented an invited paper for a special session on "The Rise of Heterogeneous Architectures: From Embedded Systems to Data Centers."
More details on each of these papers are available below.
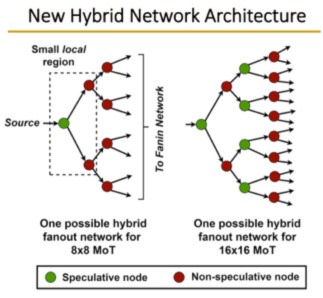
Achieving Lightweight Multicast in Asynchronous Networks-on-Chip Using Local Speculation
K. Bhardwaj, S.M. Nowick
In today's era of many-core parallel computers, efficient on-chip communication between dozens or hundreds of processors and memories is of critical importance. Borrowing ideas from the networking community, digital system designers and computer architects in recent years have embraced "networks-on-chip" (NoC's) as a solution. NoC's are structured on-chip interconnection networks to replace traditional buses, providing high performance, low power, and reliable communications.
This paper targets asynchronous, i.e. clockless, NoC's, which offer lower power and greater ease of integration of multiple components operating at varying rates, than classic clocked, i.e. synchronous, approaches. The key contribution of this work, aiming to support the needs of advanced parallel computer architectures, is to introduce a novel and efficient approach to support multicast: the transmission of one packet to multiple destinations. This capability is essential for cache coherence and multi-threaded applications.
A lightweight parallel multicast approach is proposed, for use with a variant mesh-of-trees (MoT) network topology—which is the first general-purpose multicast solution for asynchronous NoC's. A novel strategy, local speculation, is introduced, where a subset of router nodes are speculative and always broadcast. These switches are surrounded by non-speculative switches, which throttle any redundant packets, restricting these packets to small regions. Speculative switches have simplified designs, thereby improving network performance. A hybrid network architecture is proposed to mix the speculative and non-speculative nodes.
For multicast benchmarks, significant performance improvements with small power savings are obtained by the new approach over a tree-based non-speculative approach. Interestingly, similar improvements are shown for unicast benchmarks (see slide presentation).
An FPGA-Based Infrastructure for Fine-Grained DVFS Analysis in High-Performance Embedded Systems
P. Mantovani, E. Cota, K. Tien, C. Pilato, G. Di Guglielmo, K. Shepard and L. P. Carloni
The quest for energy-efficient computing is the biggest challenge in design of all sorts of computers from the smartphones in everyone's pocket to the servers running in data centers. The circuits empowering these computers are multi-core systems-on-chip (SoC) that integrate many heterogeneous components. The key to energy efficiency is precisely the ability to control each component independently and promptly so that it consumes power only when its operations are needed and at a rate that is proportional to the needed degree of performance. This require pervasive application of DVFS, a mechanism to dynamically scaling the power voltage and clock frequency at which the circuitry of each component operates.
At Columbia the groups of Carloni and Shepard have been working on the development and application of new technologies for DVFS to enable an unprecedented degree of fine-grained power management both in space (with multiple distinct voltage domains) and in time (with transient responses in the order of nanoseconds).
In this paper, they present the first infrastructure that allows SoC designers to evaluate the application of these technologies by emulating large-scale full-systems with real workload scenarios on field-programmable gate arrays (FPGA). The infrastructure provides the capabilities to continuously monitor and adaptively control the operations of each component. The authors describe the application of their FPGA-based infrastructure to three different case studies of SoCs, each combining a general-purpose processor running Linux together with ten to twelve special-purpose accelerators all interconnected by a network-on-chip. They analyze the workload's power dissipation and performance sensitivity to time-space granularity of DVFS and show that the combination of their new hardware and software solution for fine-grained power management can save up to 85% of the accelerators' energy.
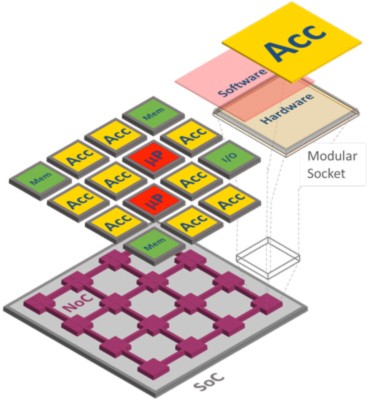
The Case for Embedded Scalable Platforms
How to simplify the design and programming of a billion-transistor system-on-chip (SoC), featuring dozens of heterogeneous components?
In this paper, Carloni addresses this question by making the case for Embedded Scalable Platforms (ESP), a novel approach that combines an architecture and a companion methodology to address the complexity of SoC design and programming. The architecture provides a flexible tile-based template that simplifies the integration of such different components as general-purpose processors and special-purpose hardware accelerators. Each component can be designed independently and plugged into the SoC through a modular socket. The socket interfaces the component with a network-on-chip that acts as the "nervous system" of the SoC as it provides inter-tile communication capabilities and per-tile adaptive control. The regularity of the tile-based organization is leveraged by the ESP companion methodology that raises the level of abstraction in the design process, thereby promoting a closer collaboration among software programmers and hardware engineers.
In presenting the key ideas of ESP, the paper brings together the contributions made by the members of the System-Level Design Group with various recent publications. Furthermore, it includes a section that describes how these ideas are the foundation of Computer Engineering Program.
Carloni presented this invited paper in a DAC special session on "The Rise of Heterogeneous Architectures: From Embedded Systems to Data Centers" that was chaired by Todd Austin (University of Michigan) and included talks by Mark Horowitz (Stanford) and Jason Cong (UCLA). Tech Design Forum has published acommentary on this event. All four participants of the special session are principal investigators in the Center for Future Architectures Research (C-FAR), one of six centers of STARnet, a Semiconductor Research Corporation program sponsored by MARCO and DARPA.
Original article can be found here.